Redundante Puppet-Master
In meinem $DAYJOB bauen wir derzeit ein zweites Rechenzentrum fertig. Es wäre
ganz schön gewesen, wenn man das als Spielwiese für Konzepte hätte benutzen
können, aber leider hat das mit der Zeitplanung nicht so ganz hingehauen,
weswegen es dann doch eher ein ziemlicher Kraftakt wurde. Das ist recht schade,
denn da gibt es ein paar Fragestellungen, die zu lösen recht interessant ist.
Wenn man z.B. bisher NFS-Server im Einsatz hat und “auf die Schnelle” nicht die
Möglichkeit besteht, die gegen z.B. GlusterFS zu
tauschen, dann stellt sie die Frage, wie man im Fall, dass man ein RZ verliert,
möglichst problemlos in das andere RZ failovern kann. Je nach Anforderung kann
es da sogar noch Bonuspunkte geben, wenn man den Failover automatisiert, aber
dabei auf Datenintegrität achtet (es muß aber keine Bonuspunkte geben - jede
Firma muß selber wissen, ob ihr der automatische Failover die zusätzliche
Technologieschicht z.B. in Form einer Clusterware mit Quorum-Knoten wert ist).
Oder auch das Thema DNS - mit den Serverfarmen auf welchem Loadbalancer sollen
denn Clients eigentlich sprechen? Und gibt es die Möglichkeit, hier überhaupt
Routing-Entscheidungen einfliessen zu lassen? Oder ist das ein typischer Fall
für Anycast? Interessante Themen, aber heute soll es um etwas deutlich
bodenständigeres gehen, nämlich um
Puppet.
Abbildung 1 Abbildung 2 Abbildung 3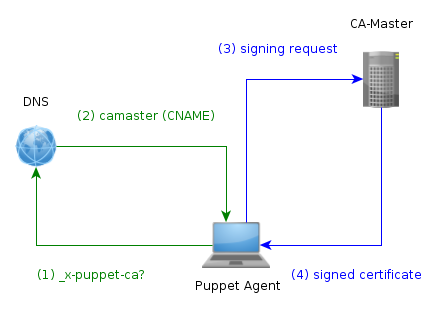
Wenn man mehr als einen Puppetmaster haben will, dann tut man das meistens entweder, weil man ein Performance-Problem hat oder weil man eine gewisse Ausfallsicherheit haben will. In unserem Fall war es die Ausfallsicherheit, und zwar besonders im Katastrophenfall. Das zu wissen ist schon mal eine große Hilfe: In unserem Setup geht nicht sofort die Welt unter, wenn ein Puppet-Agent mal nicht mit seinem Master reden kann. Der Agent wird in dem Fall einfach die letzte Katalog-Version aus dem Cache holen und diese, soweit ihm das möglich ist, anwenden. Das gilt, obwohl wir viel mit exportierten Ressourcen arbeiten, denn auch auf Hosts, die besagte Ressourcen einsammeln, stehen diese stets in der jeweils letzten Katalog-Version zur Verfügung. Wären unsere Puppetmaster also nicht verfügbar, so würde dies lediglich unsere Fähigkeit beeinflussen, im Katastrophenfall Änderungen am System durchzuführen. Unser Setup legt also Wert darauf, dass wir im Rahmen des BCM-Prozesses leicht wieder die Fähigkeit gewinnen können, unsere Umgebung zentral zu verwalten, hat aber nicht den Anspruch, vollautomatisch zu sein. Für diesen Preis, den zu zahlen wir bereit sind, erhalten wir ein relativ simples Setup, dass man auch einem Azubi gut näher bringen kann, und das trotzdem die Verteilung der eigentlichen Last - das Kompilieren von Katalogen nämlich - auf mehrere Server erlaubt.
Dieser KISS-Philosophie folgend habe ich denn auch den Technologiestack aufgebaut. Die Installation läuft unter CentOS 6 und benötigt lediglich die von Puppetlabs bereitgestellen yum-Repositories sowie den Passenger-Gem. Der ganze Stack besteht aus:
- Apache httpd als Frontend
- Phusion Passenger als Rack-Middleware-Server, welcher dann Puppet ausführt (via rackup)
- Puppet selbst ;-)
- als Datenbank für Reports, Kataloge, Fakten und exportierte Resourcen wird PuppetDB genutzt
- Backend für die PuppetDB ist ein PostgreSQL, welches direkt auf den Puppetmastern läuft
- Als Frontend für Nutzer kommt puppet-dashboard zum Einsatz
Erstes Ziel war es nun, in diesem Technologiestack die SPOFs (Single Point of
Failure) zu identifizieren. Und hier hat man gleich eine Hürde zu meistern,
welche in der Art liegt, wie Puppet Clients authentifiziert: Im Hintergrund
verwaltet der Puppetmaster nämlich eine komplette
CA. Jeder Client muß, um
mit dem Master kommunizieren können, ein von dieser CA unterschriebenes
Client-Zertifikat vorlegen, welches er normalerweise bei der ersten
Inbetriebnahme erhält, entweder über eine automatische Signatur oder via
manuellem Eingriff eines Administrators. Was Puppet leider nicht kann ist die
zur CA gehörigen Daten wie z.B. die Seriennummern bereits erteilter Zertifikate
etc. abzugleichen. Nun unterstützt Puppet zwar ab Version 3.0 den Einsatz von
SRV-Records,
um direkt aus dem DNS seinen CA-Master zu finden und kann dann auch durchaus mit
mehr als einem CA-Master (also einem Puppetmaster mit der Einstellung ca = true) umgehen, dies erfordert jedoch dann zusätzliche Logik, um die
Multi-Master-Replikation vernünftig in den Griff zu kriegen. Da die Aufnahme von
neuen Hosts etwas ist, das zumindest bei uns nicht so oft vor kommt, habe ich
mich hier für eine Abkürzung entschieden: Der SRV-RR zeigt auf einen CNAME,
nämlich puppet-camaster. Zur Folge hat dies allerdings, dass alle Puppetmaster
ihr Zertifikat initial mit einem Subject Alternative Name anfordern müssen.
Eine Übersicht darüber, wie ein neuer Client nun aufgenommen wird, findet sich
in Natürlich reicht das alleine nicht, es müssen auch die eigentlichen CA-Daten
zwischen den einzelnen Puppetmastern synchronisiert werden, dies ist allerdings
relativ trivial, da die Replikation nur in eine Richtung erfolgen muss, weswegen
hier ein simpler rsync-Aufruf auf das betroffene Verzeichnis ausreichend ist.
Die einzige Besonderheit ist hier die CRL: Diese wird vom Puppetmaster jedesmal,
wenn ein Agent gelöscht/deaktiviert wird, aktualisiert. Der Apache-Webserver
benutzt nun eigentlich diese Liste, um Clients mit zurückgerufenen Zertifikaten
erst gar nicht zum Puppetmaster durch zu lassen. Das Problem an der Sache ist
aber natürlich, dass diese CRL stets nur auf dem CA-Master aktuell ist. Das
Problem ist jedoch kein besonders großes: Auch auf den Puppetmastern läuft
natürlich ein Puppet-Agent - und dieser lädt bei jedem Lauf eine Kopie der CRL
herunter. Trägt man diese im Apache ein, so hat man hier nach jedem Lauf des
Agents auf den Mastern aktuelle Daten.
Der Aufbau der restlichen Master ist relativ trivial: Es ist lediglich darauf zu
achten, dass diese mit der Option ca = false gestartet werden - und natürlich
sollten sie stets das gleiche Regelwerk wie die anderen Puppetmaster erhalten,
was jedoch in unserem Setup, in dem das Regelwerk im git hinterlegt ist, kein
großes Problem darstellt. Ein Puppet-Agent, der bereits ein Zertifikat erhalten
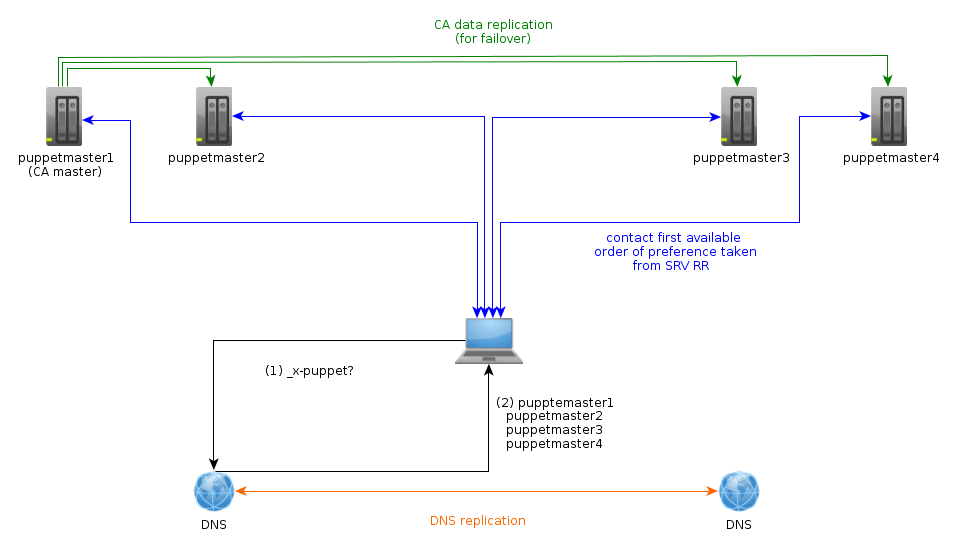
hat, wird sich dann anhand eines DNS-Records einfach den jeweils günstigsten und
erreichbaren Master suchen. Um dies für unser Setup möglichst gut auszunutzen
haben wir uns im Prinzip zwei Tricks zu nutze gemacht:
- Unsere Server können via facter feststellen, in welchem Rechenzentrum sie
sich befinden. Diese Information machen wir uns zu nutze, um den Parameter
srv_domainauf eine DNS-Zone zu setzen, welche die für das jeweilige Rechenzentrum optimale Liste an SRV-Records enthält, also z.B.srv_domain = datacenter1.example.net. - Die in der jeweiligen DNS-Zone hinterlegten SRV-Records zeigen mit niedrigster Prioriät (die Logik ist da umgekehrt, wie bei MX-RRs) und jeweils gleicher Gewichtung auf die Puppetmaster, welche sich im selben Rechenzentrum befinden und mit höherer Priorität (und wiederum gleicher Gewichtung) auf die Puppetmaster im jeweils anderen Rechenzentrum.
Dies funktioniert so gut, dass man einen einzelnen Puppetmaster abschießen kann, während der Agent gerade mit diesem kommuniziert - der Agent wird hierbei nur eine Warnung loggen und einfach einen der anderen Puppetmaster ausprobieren. Wie man in Abbildung 2 erkennen kann, sind für diesen Fall also wirklich alle Puppetmaster gleichwertig, was einem viel Spielraum bei Lastverteilung und Failover lässt. An dieser Stelle könnte man annehmen, dass man soweit alles erledigt hat, allerdings ist dem nicht so, es müssen noch die anderen Stellen des Technologie-Stacks abgeklopft werden.
Die PuppetDB selbst ist zunächst einmal unproblematisch: Da sie selbst keine
Daten speichert, sondern sich dafür auf PostgreSQL verlässt, gibt es zunächst
einmal keinen Grund anzunehmen, dass man hier etwas anderes als den
Aktiv-Aktiv-Betrieb würde haben wollen. Im Gegenteil, mit dem eingebauten
Queueing ist sie bestens dafür gewappnet, auch mal einen Ausfall der Datenbank
zu überstehen (solange man nur schreibt und nicht liest, also z.B. keine
Resourcen einsammeln will oder JSON-Queries dagegen stellt). Die
Authentifizierung ist ebenfalls komplett in die Puppet-CA integriert, so dass es
keine Sicherheitsprobleme gibt. Der Teufel steckt hier jedoch im Detail, genauer
in PostgreSQL. Die mit CentOS 6 gelieferte Version dieser relationalen Datenbank
lässt eigentlich ohne größere Kopfstände nur eine Möglichkeit zu, eine
Datenredundanz auf mehr als einem Knoten herzustellen, nämlich den Aufbau einer
sog. Warm-Standby-Datenbank mittels WAL archivelog
shipping. Dank des
mitgelieferten Utilities pg_standby ist es zwar trivial, so ein Setup
aufzusetzen und auch der Failover ist mit einem simplen touch-Befehl gut
machbar, aber die PuppetDB muss ja wissen, auf welchem Hostnamen die
PostgreSQL-DB läuft. Nun kann man natürlich definieren, dass die aktive
PostgreSQL-Datenbank stets auf dem CA-Master läuft und in PuppetDB als
Datenbankserver eben jenen CNAME-Record hinterlegen, im Failover-Fall bedeutet
dies jedoch, dass man einem weiteren Dienst neu starten muss. Ferner müsste man
sich dann auch Gedanken um die Absicherung der PostgreSQL-Datenbank machen. Da
wir derzeit nicht den Bedarf haben, direkt auf die PostgreSQL zuzugreifen, habe
ich mich dafür entschieden, die SQL-Datenbank nur an localhost lauschen zu
lassen und in den Puppetmastern als PuppetDB stets den CNAME zu hinterlegen. Im
Failoverfall muss man die Puppetmaster sowieso durchstarten (siehe Anmerkungen
weiter unten zu puppet-dashboard), das ist also kein zusätzlicher Aufwand. Die
PuppetDB selbst kommt übrigens gut damit klar, wenn sie auf eine
Standby-Datenbank losgelassen wird - sobald die SQL-Datenbank in den Primärmodus
überführt wird, steht auch die PuppetDB zur Verfügung.
Die letzte zu betrachtende Komponente ist das puppet-dashboard. Bei diesem gibt
es momentan ein gewichtiges Problem: Für die Verarbeitung der Reports, die dann
erst das Darstellen der Übersicht über alle Puppet-Nodes ermöglichen, ist man
derzeit leider noch darauf angewiesen, dass diese Reports vom Puppetmaster via
http an das Dashboard gepostet und dort als YAML auf der Festplatte des Servers
zwischengespeichert werden. Zwar unterstützt PuppetDB die Speicherung von
Reports seit mindestens Version 1.4, allerdings befand sich diese Funktionalität
bis zur Version 1.5, die erst kürzlich erschienen ist, noch im sog.
“experimental-API”-Bereich. Somit ist es auch hier einfacher, stets nur eine der
beiden Instanzen aktiv zu benutzen, und wiederum bietet sich der für den
CA-Master benutzte DNS-Eintrag ein. Im Failoverfall kann man den CNAME verbiegen
und die Puppetmaster neu starten, woraufhin diese die Adressänderung mitbekommen
und die Reports an den neuen, aktiven puppet-dashboard-Server schicken. Das
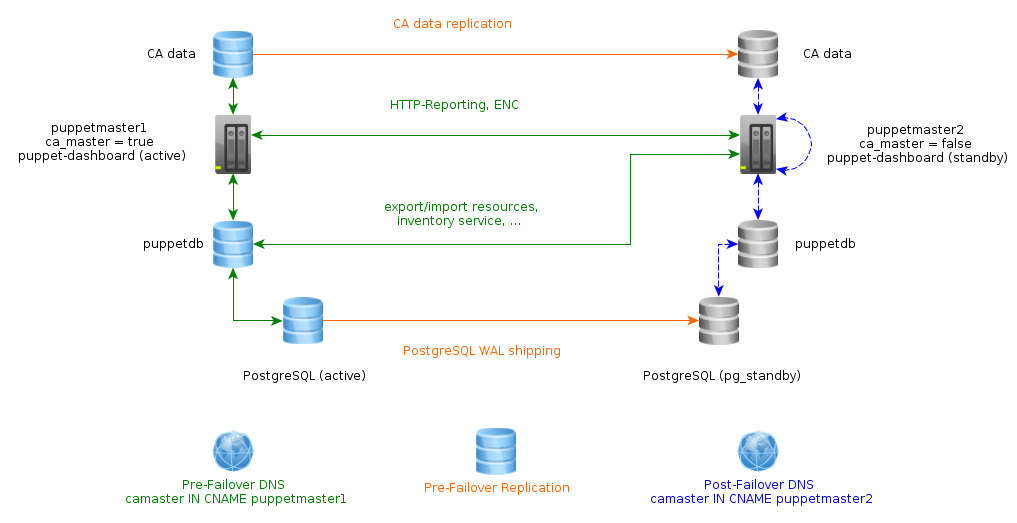
Setup als ganzes, welches auch in Abbildung 3 zu sehen ist, sieht also
folgendermaßen aus:
- Die Dienste PuppetDB, PostgreSQL und puppet-dashboard werden stets nur auf einem Host aktiv betrieben.
- Dieser Host ist stets über den CNAME-Record
camasteridentifiziert. - Die CA-Daten werden stets vom CA-Master auf alle weiteren Puppetmaster repliziert, dort aber erst im Failover-Fall benutzt.
- Die PostgreSQL-Datenbank wird ebenfalls permanent auf alle weiteren Puppetmaster repliziert.
- Die Verteilung der eigentlichen Arbeit im Normalfall erfolgt über SRV-Records, die die Last je nach Standort auf verschiedene Master verteilen.
Wie sieht nun das Failover im BCM-Fall aus? Nun, relativ einfach:
- Anpassen des CNAME-Records für
camaster, so dass dieser auf einen der überlebenden Puppetmaster zeigt. - auf dem neuen CA-Master:
vi /etc/puppet/puppet-master.conf, dortca = truesetzen. - auf dem neuen CA-Master: promoten der PostgreSQL-Datenbank mittels
touch /var/lib/postgres/pg_main/data/promote.trigger - auf allen Puppetmastern:
service httpd reload
Der dafür erforderliche Zeitaufwand war in unseren Szenarien deutlich kleiner als 30 Sekunden - am längsten hat die Replikation des geänderten CNAME-Eintrags gedauert. Alle anderen Replikationen etc. habe ich durch sorgfältiges Skripten (i.e. es wird überprüft, ob der aktuelle Knoten ein CA-Master ist oder nicht) erschlagen, so dass keine weiteren Eingriffe notwendig sind. Wie bereits erwähnt kann man sich hier noch deutlich mehr “verkünsteln”, mir war jedoch wichtiger, das Setup möglichst übersichtlich zu halten - der Failover-Fall sollte ja nicht der Normalfall sein.
Ich höre jetzt Princess Crocodile von Gry F.M. Einheit - mehr Electro-Swing braucht das Land!